Everything You Need to Know about CSS Regression Testing

In the age of online business, the visual identity and the business identity of a company are steadily intertwined. Successful businesses carefully pursue an expressive, but cohesive visual identity for their websites, and rely on the entire range of modern web capabilities in an effort to effectively communicate their brands’ message. This is no accident: websites are carefully designed and curated because the flawless image they present visually goes hand in hand with the flawless business reputation they need to project.
This extraordinary communication potential relies on CSS, a powerful and flexible language that is used to describe the visual layout and rendering rules of a web page -- its style, in a word. However, the flexibility of this language is a double-edged sword: CSS is not only versatile but also easy to break and difficult to test.
CSS bugs are immediately visible -- they show up as unmistakable glitches or inconsistencies that instantly break the carefully cultivated image of a professional website. But they are not visible everywhere. CSS changes routinely result in subtle visual bugs that are only visible at specific browser window sizes, on specific devices or screen orientations, on certain browser versions, and so on.
This makes CSS regression testing uniquely challenging. A single page has to be carefully checked under an extensive set of conditions. Logistics aside, the human mind is ill-suited for this task. When it comes to modern, responsive designs, CSS regression testing is not something that human operators can reliably do without aid.
How Do CSS Defects Creep in?
In order to understand what makes CSS regression testing so difficult, let’s start with a quick breakdown of how buggy CSS changes creep into a project.
CSS style rules describe how page elements are to be rendered by your browser – their size, position, color, the font used for every piece of text, and so on. The set of CSS rules that a page includes are applied every time the page is rendered, so they have to cover every browser out there, on every device, with a screen of any size that a user may hold at any angle.
Consequently, not all the rules described in a CSS stylesheet are simultaneously applied on a given page.
Obviously, some rules cover elements that may simply not be present on a page – e.g. rules about how form elements are to be displayed aren’t going to be used on a page that doesn’t have any form elements.
But more importantly, some rules are only applied in certain cases. For example, CSS style rules that cover rendering rules for narrow screens may not be applied when rendering the page on a laptop, in a full-screen browser window.
There are many combinations of device types, screen size and orientation, window sizes, browser versions, and so on – far too many for a developer to reliably keep in mind at all times, or for a tester to manually cover.
This is why CSS bugs are so easy to introduce, and so hard to spot. They creep in very easily, and they can remain undetected for so long.
How to Test CSS Code
So how do you test CSS code? Clearly, you can’t just wait for your customers to tell you when your website is broken!

A simple, low-effort solution is to integrate a CSS linter in your development or CI framework. A tool like `csslint` can catch CSS syntax errors and glaring deviations from standard best practices. These can catch a surprising amount of real-life bugs before the QA testing team even gets to take a stab at it.
However, most bugs aren’t caused by syntax errors, they’re caused by logical errors. They can be introduced not just by changes made in-house, but also by CMS or plug-in updates. They don’t result in any error messages – the browser is happy with the rendering instructions it gets – it’s just that the instructions are wrong.
Wrong, that is, in visual terms – in ways that only humans can perceive. This is why CSS regression testing is fundamentally visual in nature.
At the most basic level, a CSS regression test can be performed by comparing a screenshot of a page back when it was in a known good state – before a CMS update, for example – to a screenshot of how the page looks now. If the two images aren’t identical, this can indicate a defect.
This procedure, called visual regression testing, sounds easy enough, but remember that this has to be replicated across all the pages and interaction features of a website, on every platform, browser, and device type that a customer can be reasonably expected to use. This has two problems.
First, there’s the problem of sheer effort. Even on a website with relatively few pages, if you factor in just a few laptop screen sizes and the most 5 most common phone screens in your target geographies, that’s still a lot of screenshots to check!
Second, and more importantly, there’s the problem of detection rate. Due to a phenomenon known as change blindness, the chances of a tester missing a subtle difference between two images is pretty high and tends to increase with the volume of work.
But your customers don’t look at thousands of before-and-after pictures of your website: an error that the most attentive tester will fail to spot after four hours of looking at website screenshots will be immediately obvious to someone who clicked on a link to your website.
Automating CSS Regression Testing Tool
These two factors – high effort and the limit of human perception – are the main driving forces behind automatic CSS regression testing solutions. The idea is to leverage the things machines are good at – performing a repetitive task at a high rate – while keeping humans in the loop for the things they are good at – making design trade-offs decisions, prioritizing bugfixes and so on.
Visual regression testing is conceptually sound. It is inherently tuned to detect defects that have an immediate and obvious customer impact and relies on objective metrics that keep testing reports noise-free.
Since many CSS bugs are inherently difficult to spot, as they only occur under certain conditions, CSS style changes are a natural candidate for automated regression testing.
Which Method of CSS is Best for Testing
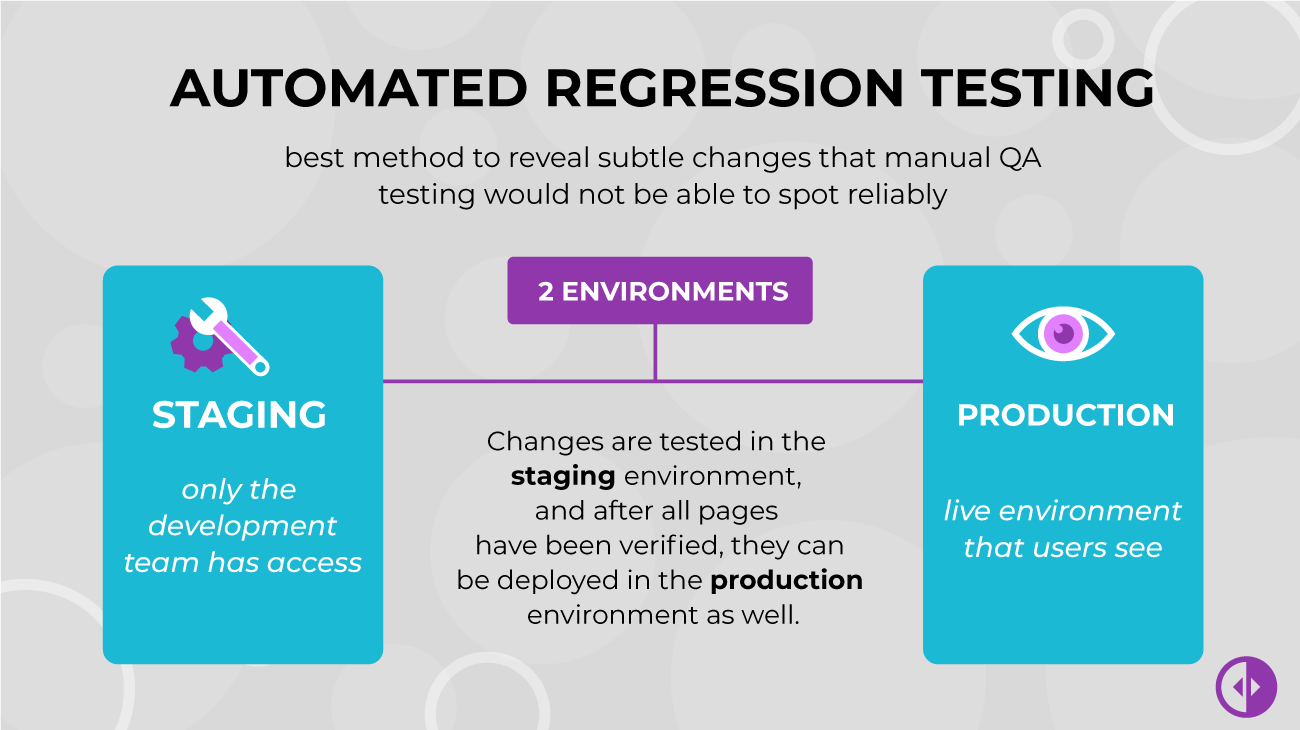
Automatic CSS testing is the most reliable way of detecting breaking changes after a CMS update, or after updating plug-ins and themes. It can reveal subtle changes that manual QA testing would not be able to spot reliably and can be easily integrated into any development, QA, and deployment process.
The most straightforward integration solution is to perform regression testing before deploying potentially breaking changes. Usually, that’s done by maintaining two environments – a “staging” environment, where only the development team has access, and a “live” or “production” environment, the public server where the actual website gets deployed and which customers see. Changes are tested in the staging environment, and after all pages have been verified, they can be deployed in the production environment as well.
The staging/production deployment strategy isn’t inherent to automated regression testing though. For low-volume websites, the risk of deploying straight to production may turn out to be acceptable. In this case, deployment is done straight into production, but only after making a backup. If potentially breaking changes are identified afterward, during regression testing, the backup can be restored.
However, automating CSS regression testing allows you to integrate regression testing in earlier stages of the development process. For example, visual testing tools like Diffy expose a REST API that allows you to integrate regression testing jobs into a CI pipeline. This way, every commit and pull request can be tested separately, throughout the development phase.
Early integration of CSS regression testing has multiple benefits. Defects are easier to fix when caught early, and steady schedules are easier to keep because you don’t have to keep going back and fix issues you didn’t know about.
Don’t stress about bugs that your visitors will catch before you do. Sign up to Diffy to make sure your visual regression testing is on point!